

Blogs
Date 29 June 2026
We recently discussed how effective intelligent automated alerting could be. This is great in theory but how does this fare in the real world? As mentioned previously we’ve been automating some of these techniques to use with our managed services. Here are a few examples of things our own Operational Capacity Management analysis engine (OCM) was able to pick out using the techniques discussed.
Using one of the interfaces built into our engine, it got to work looking at servers monitored by SCOM (Systems Center Operations Manager) - within minutes we were detecting changes and alerting on over 2,000 servers and counting.
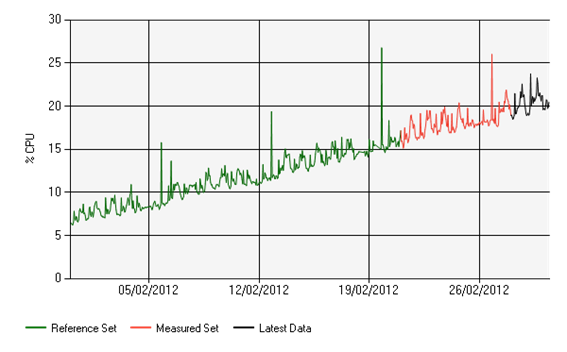
Taking ATASF/Growth alerting, the analytics managed to pick up that there was some substantial linear growth in this server processor utilisation even though it has not breached any fixed threshold:
A quick remediation procedure found that some forgotten developer code was left on this machine and was slowly consuming more or more resources as time went on. Had this process continued we would have been alerted by our fixed threshold but by then it would have been too late to stop this server from becoming unstable.
Looking at Hum alerting, the relevant techniques managed to pick up that this server below was on average consuming 32% CPU, again our fixed threshold alerting would have considered this to be not an issue:

A quick remediation procedure found that some profiling tools were left active on this server. This elegant alerting used managed to acknowledge that there is a problem and stopped it from becoming an issue.
What’s great about intelligent alerting is you could use this information to build forecasts to understand when these servers could become an issue:

The above was using a times series decomposition technique built into OCM across a server that was demonstrating high growth. Extrapolating this growth, OCM managed to identify not only that this server was growing in CPU capacity required but also when it could start becoming an issue.
So it turns out intelligent alerting is a very useful technique if done correctly. With the use of the OCM analysis engine we could detect abnormal behaviour before it became an issue, all with a few clicks thanks to automation.
If you would like to see some more examples or would like to share your experiences with this methodology please feel free to reply.

About the author
Team Capacitas

FinOps and AI: Building the Financial Discipline for the Next Wave of Enterprise Intelligence
AI FinOps represents an evolution rather than a replacement of traditional FinOps. It extends the model into a domain where financial, technical, and product decisions are tightly interconnected.

Confidence Under Load: How We Verified AKS Readiness for Peak
How Capacitas verified AKS readiness for peak demand by validating workload performance, autoscaling, cluster capacity, monitoring, and incident response.

Building Cloud Resilience: Lessons from the AWS Outage
Learning from the Latest Outage. Events like this week’s AWS disruption highlight one clear truth: resilience must be designed, not assumed.

Bringing Order to Chaos: A Practical Guide to Chaos Testing in the Cloud
In today’s cloud-native environments, resilience is not optional—it’s critical. Chaos testing has emerged as a key practice for validating system behaviour under failure conditions.

